Choisir Kubernetes comme orchestrateur
Docker est une technologie nous permettant de construire des applicatifs encapsulé dans des conteneurs et exportable d’un environnement à un autre avec peu de difficulté. Nous commençons donc à construire des sortes d’unités applicatifs, manipulable très facilement, se lançant et s’arrêtant avec une simple commande Docker. Cette simplicité de gestion des conteneurs nous amène à construire de plus en plus d’applicatif sous Docker, amènent les équipes de développement à concevoir un nouveau type d’architecture : les microservices.
Les microservices nous permettent de concevoir des applications plus petites, focalisés sur un domaine fonctionnel bien précis de l’ensemble du système. Au vu de la légèreté des conteneurs, l’objectif des microservices est de faire fonctionner plusieurs conteneurs côté à côté afin d’encaisser au maximum les charges induits par l’utilisation du système d’information.
La gestion de plusieurs conteneurs devient ainsi une problématique beaucoup plus grande que par le passé. Peut-on faire fonctionner plusieurs conteneurs différents côte à côte ? Comment gérer la création / suppression des conteneurs de manière automatique selon la charge ? Afin de répondre à ces problématiques, Google a rendu open-source l’un des outils qui permettait justement à l’entreprise de gérer ses conteneurs en interne sur lesquels fonctionnaient ses applications : Kubernetes.
Kubernetes est une plateforme d’orchestration open source de conteneurs permettant entre autres d’automatiser le déploiement et la gestion d’applications multi-conteneurs scalable. Kubernetes fonctionne de pair avec Docker : votre application fonctionne dans une image Docker, cette image va être géré par Kubernetes afin de s’assurer que l’image, répliqué X fois selon les usages, fonctionne correctement.
L’orchestrateur est cependant compatible avec n’importe quelle technologie de conteneur conforme au standard Open Container Initiative. Docker a également développé son propre orchestrateur : Swarm. Cependant, Kubernetes est devenu plus populaire et semble avoir été adopté plus largement par la communauté.
L’architecture de Kubernetes est représentée par le diagramme ci-dessous :
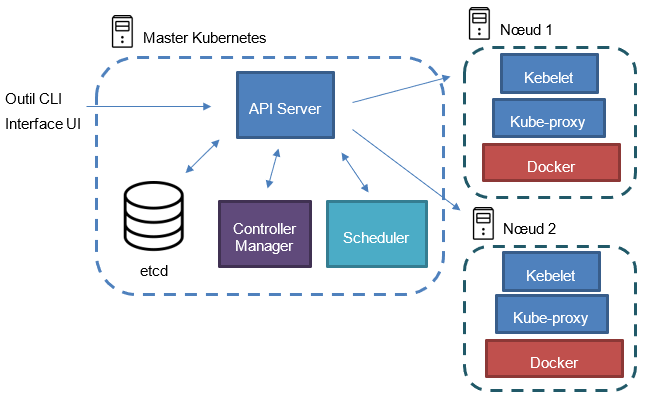
Un cluster Kubernetes est constamment composé d’un nœud master, les autres nœuds sont des nœuds enfants qui seront pilotés par le nœud master. Le nœud master est composé des outils Kubernetes suivant :
- API Server : également appelé kube-apiserver, l’API Server est le composant central de gestion du cluster Kubernetes. Il permet en exposant des API REST de manipuler le cluster et ses nœuds via les fichiers de configuration. Il permet également de stocker l’état du cluster dans le stockage etcd ;
- Controller Manager : composant de Kubernetes permettant de ‘surveiller’ le cluster, et d’agir si nécessaire. C’est lui qui permet au cluster de maintenir son état de fonctionnement, c’est-à-dire l’état décrit dans le dernier fichier de configuration. Il vérifie que les nœuds fonctionnent toujours, et le cluster respect le bon nombre de réplica d’un service déployer au sein de celui-ci ;
- Scheduler : entité qui va planifier le déploiement d’un pod sur un nœud. Le planificateur va prendre en compte beaucoup de paramètre pour décider sur quel nœud il faut déployer le pod : les ressources serveurs et logiciels, les contraintes, les spécifications d’affinités, les interférences …
- etcd : stockage persistent de type NoSQL avec clé/valeur permettant à Kubernetes de connaître à tout moment l’état supposé du cluster.
Il est ensuite possible de communiquer avec l’API Server via une interface en ligne de commande ou via une interface graphique. Ensuite, Kubernetes manipule ce qu’on appelle des objets. Il en existe plusieurs types, et il est important de bien connaître la terminologie :
- Pod : c’est l’entité la plus unitaire de Kubernetes, la plus petite et la plus simple. Un Pod représente un processus en cours d’exécution dans le cluster. Nous pouvons comparer cela à Docker : les images sont à Docker ce que les Pods sont à Kubernetes. Un Pod encapsule une application (ou plusieurs selon certains cas, mais non conseillé) et possède une ressource stockage, une adresse IP et des options qui dicte comment le Pod doit se comporter. Il représente une unité de déploiement et correspond au final à une seule instance d’une application dans Kubernetes ;
- Service : un service est un ensemble de Pod regroupé sous une même enseigne logique : les labels. Les services deviennent une abstraction des Pods permettant à Kubernetes de savoir quels Pods sont concernés par quelle facette fonctionnelle de votre application ;
- Volume : un Pod a une durée de vie indéterminé. S’il tombe, Kubernetes va recréer ce Pod à l’identique selon la configuration indiquée. Ainsi tous les fichiers de l’ancien Pod sont perdus. Les volumes apportent une solution permettant de faire perdurer les fichiers, mais la durer de vie reste celle du Pod. Le volume permet cependant de conserver les fichiers même si des conteneurs sont tombés dans le Pod ;
- Namespace : les namespaces permettent de diviser un cluster afin de faire fonctionner plusieurs environnements à l’intérieur (développement, production …). Cette division est une division logique, et permet par exemple de diviser les ressources à l’intérieur du cluster selon le namespace choisi.
Kubernetes permet 2 modes de modification du cluster : le mode déclaratif par opposition au mode impératif. Le mode impératif demande à l’administrateur du cluster d’écrire les commandes qui vont changer le cluster. Par exemple, les commandes ci-dessous permettent de créer un namespace, un quote, un déploiement et un service.
kubectl create ns ghost kubectl create quota blog --hard=pods=1 -n ghost kubectl run ghost --image=ghost -n ghost kubectl expose deployments ghost --port 2368 --type LoadBalancer -n ghost
L’administrateur exécute lui-même les commandes, et doit ensuite lui-même s’assurer que le cluster maintien le bon état. Par exemple, si un Pod tombe, c’est à lui de relancer le pod avec les commandes appropriées. De plus, une fois le cluster dans l’état final, il est difficile de se souvenir de l’état désiré du cluster, il n’y a pas de source of truth.
Cette technique comporte bien des soucis notamment en termes de maintenabilité de l’état du cluster. C’est pourquoi il existe la méthode déclarative. Cette méthode permet d’utiliser des fichiers de configuration au format au YAML afin de piloter de cluster. Ces fichiers YAML sont établis par l’administrateur du cluster, et sont ensuite soumis à Kubernetes via la commande suivante :
kubectl apply -f <monFichier>.yaml
Avec cette commande, Kubernetes va vérifier l’état du cluster en fonction de ce fichier de configuration. S’il trouve une différence, Kubernetes va automatiquement lancer les commandes nécessaires afin de faire correspondre l’était du cluster avec le fichier de configuration. Ensuite, cette configuration est stockée de manière persistante dans etcd. Cette méthode possède plusieurs avatanges :
- C’est Kubernetes qui s’occupe de lancer les commandes en fonction des différences trouvés. L’administrateur décrit l’état de du cluster au final et non plus les commandes qui amènent à cet état ;
- L’état est sauvegardé et donc Kubernetes connaît constamment l’état du cluster ;
- Kubernetes surveille le cluster et compare avec l’état souhaité soumis avec ces fichiers de configuration. Il va donc lancer les commandes nécessaires si une anomalie devait se produire.
Les fichiers de configuration semblent donc être la meilleure solution afin de gérer un cluster Kubernetes. Ces fichiers au format YAML possèdent doivent respectés un schéma bien particulier afin d’être compris par Kubernetes. Il est important de rappeler que YAML est une version dérivée de JSON. Cela veut dire que vous pouvez très bien aussi utiliser des fichiers au format JSON pour piloter le cluster. Pour tester Kubernetes en local sur votre machine, il est possible d’installer Minikube (disponible sur Mac, Linux et Windows). Cet outil permet de simuler des nœuds dans des machines virtuelles et ainsi tester vos déploiements : https://kubernetes.io/docs/setup/minikube/.
L’exemple ci-dessous présente la création d’un Pod via un fichier de configuration YAML :
apiVersion: v1
kind: Pod
metadata:
name: my-site
labels:
app: web
spec:
containers:
- name: front-end
image: nginx
ports:
- containerPort: 80
- name: my-site
image: myRegistry/mySite:v1
ports:
- containerPort: 88
Les fichiers Kubernetes commencent toujours par apiVersion. Ceci permet de cibler la version du schéma Kubernetes que vous souhaitez. Ensuite, on indique quel type d’objet Kubernetes on souhaite créer via l’attribut kind. Ici, nous voulons un Pod. Une bonne pratique est de constamment rajouter des métadonnées à ses objets. Dans le cas ci-dessus, on rajoute un name et un label. Dans la section spec, le fichier décrit les images docker que Kubernetes doit télécharger. Dans ce cas, on utilise une image nginx et une image personnalisée de l’application que l’on souhaite faire fonctionner dans le Pod. Une fois ce fichier bien conçu, il suffit de lancer la commande suivante :
> kubectl create -f pod.yaml
Au bout d’un moment, le Pod passe en statut Running, confirmant bien que la création s’est déroulée avec succès.
Grâce aux fichiers de configuration, il est très facile de piloter et maintenir un cluster Kubernetes. Les architectures micro-services doivent se doter d’orchestrateur afin de garantir une haute disponibilité des applicatifs. Kubernetes est un excellent choix dans ce sens notamment par sa robustesse et sa flexibilité de gestion. Aujourd’hui répandu mondialement, ce projet Open Source est parfait exemple d’outil développé par la communauté et qui sert au plus grand nombre.