Comment concevoir son architecture microservices
L’architecture microservice est un type d’architecture logicielle émergent tentent de répondre aux problématiques des applications dites Monolithiques à savoir : développement fastidieux, aucune flexibilité, difficulté de déploiement, zéro scalabilité … Le principe des microservices est simple : on décompose l’application en plusieurs applications plus petites et plus autonomes gravitant autour d’un Business Domain. Tout l’intérêt des microservices est de se recentrer sur le métier et les problèmes fonctionnels que l’application tente de résoudre.
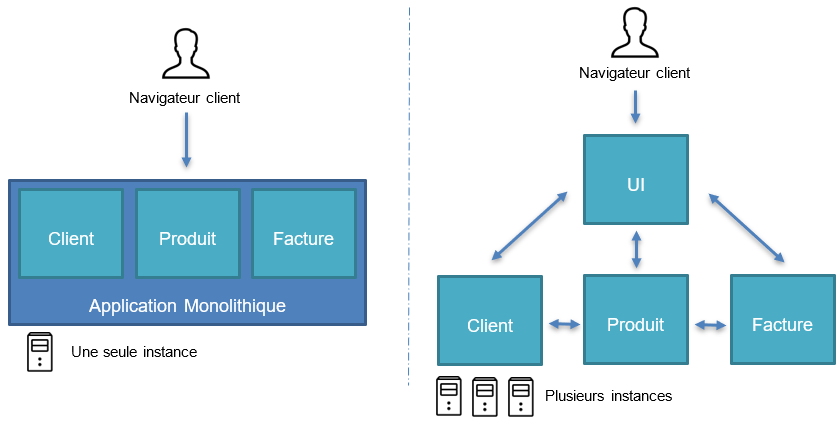
Les microservices ont l’avantages d’être plus petits, et donc plus flexible en termes de développement, déploiement et maintenabilité. Chaque microservice se doit de répondre à un aspect métier, on appelle un Contexte Délimité (Boundary Context an anglais). Tout l’enjeu de l’architecture microservice est ici : s’assurer que la délimitation en domaine fonctionnel est suffisamment pertinente et cohérente pour assurer des microservices aussi petit que possible mais suffisamment autonome.
La taille des microservices est là le piège de cette architecture. Il paraît évident que plus les microservices sont petits, plus il sera facile de les gérer. Cependant, on peut s’apercevoir très vite que certains microservices communiquent beaucoup entre eux, car ils ont souvent, voir systématiquement besoin des informations de l’autre pour fonctionner. Si un tel comportement est observé, cela veut dire que deux microservices ne doivent former qu’un.
Ceci est tout l’enjeu des contexte délimités. L’analyse préalable architecturale d’une solution en microservice doit aboutir à la séparation du business model initial en plusieurs contextes délimités les plus petits et autonomes possible. La cohésion est le maître mot ici. Chaque contexte doit être suffisamment cohérent avec lui-même afin d’éviter le surplus de communication avec les autres.
Le concept Domain Driven Design (appelons le DDD) est une méthode mettant en œuvre absolument tous les concepts que nous venons de citer ci-dessus. Lors de la phase d’analyse de l’architecture du projet, le DDD aide dans la phase de découpage en contexte délimités afin d’identifier les sous-domaines devenant par la suite les microservices.
Le DDD a été pour la première fois introduit par Eric Evans en 2004 dans son livre Domain-Drive Design: Tackling Complexity in the Heart of Software. Aujourd’hui répandu mondialement, je vous conseille fortement cette lecture extrêmement intéressante
Lors de la conception des microservices, le code est souvent divisé en couche. Cette division en couche est à la fois conceptuelle et technique, cela permet aux développeurs de mieux reconnaître les différentes parties de l’application en séparant d’une manière bien précises les entités qui composent le code. Ces couches sont des abstractions logiques destinés à mieux comprendre le code.
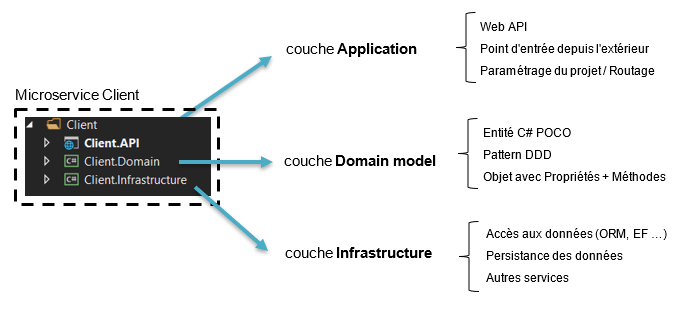
En quelques mots, voici comment nous pourrions définir les différentes parties représentées ci-dessus :
- Application : contient la partie opérationnelle du microservice en exposant le métier et le domaine model vers l’extérieur. Cette couche contient ainsi tout le paramétrage et le code nécessaire afin que le microservice puisse exister et fonctionner dans un environnement qui est le sien. Cette partie ne connaît pas le business, et s’occupe simplement de coordonner les interactions entre les autres couches et/ou le monde extérieur ;
- Domain model : représente les concepts propres au business que le microservice de traiter dans le système d’information. L’était propre du service est représenté dans les entités de cette couche, et représente clairement le cœur du business du microservice ;
- Infrastructure : représente comment les données sont stockés en base de données (ou autre).
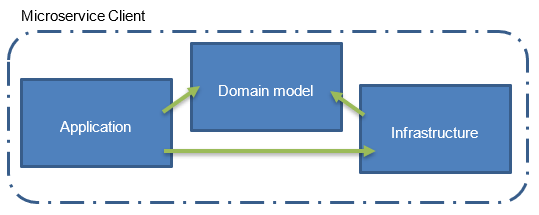
Les dépendances entre les différentes couches sont importantes et ne doivent pas se faire de manière aléatoire. Dans un premier temps, la couche Domain model ne doit pas avoir de dépendance avec les autres couches. La librairie doit rester neutre, elle est exploitée dans les autres librairies en tant que dépendance. Ensuite, la couche Infrastructure n’a qu’une seule dépendance vers le Domain model. Cela paraît évident puisque c’est elle qui est responsable de la persistance des données. Il faut donc les modèles permettant de symboliser les entités de la base de données. Enfin, la couche Application possède des dépendances vers les 2 car :
- Elle a besoin des services disponibles dans Infrastructure afin d’effectuer les actions / traitements nécessaire pour traiter les requêtes entrantes et répondre aux besoins métiers ;
- Elle a besoin des modèles du Domain model pour faire transiter / créer / mettre à jour les données ;
La couche Application est un peu l’orchestrateur des autres couches.
La notion de Domain model étant très importante, il est indispensable de bien découper ses contextes afin d’avoir une cohérence dans les entités. Une entité, au sens que l’identifiant de cette entité est le même au travers de plusieurs microservices, peut être partagé dans tout le système, mais pas forcément sous le même modèle. Par exemple, prenons une entité Acheteur et Facture et 2 microservices créé spécialement permettant de gérer les 2 de manière indépendante. Le microservice Acheteur va bien évidemment avoir un modèle très complet de l’acheteur, cependant le microservice Facture n’a pas besoin d’un modèle aussi complet : dans l’absolue l’identifiant de l’acheteur suffit, mais d’autres propriétés peuvent intervenir si le besoin est là. Le contexte de chaque microservice influe sur son Domain model.
Une autre règle est très importante en DDD :
« Chaque entité du Domain model doit contenir les données et les comportements qui lui sont propre selon son contexte. »
Cela veut tout d’abord qu’on ne créé pas de modèle dit DTO (Data Transfer Objects), mais des modèles POCO (Plain Old CLR Object), c’est-à-dire contenant du comportement. Selon Martin Fowler et Eric Evans, précurseurs du DDD, utiliser des DTO avec classes de services donnerai des anti-patterns comme du code spaghetti ou des scripts transactionnels. On parle alors de domaine anémique. Pour des microservices simples (type CRUD), cela pourrait suffire mais dans le cadre d’un système complexe avec plusieurs microservices, la bonne pratique est d’utiliser des modèles POCO, c’est-à-dire contenant les données et les méthodes permettant de gérer ses données (ajout, modification …).
Martin Fowler explique clairement cette différence dans plusieurs de ses articles : https://martinfowler.com/bliki/AnemicDomainModel.html et https://martinfowler.com/eaaCatalog/domainModel.html.
De ce fait, au sens de Martin Fowler et Eric Evans, les entités doivent ressembler à ceci :
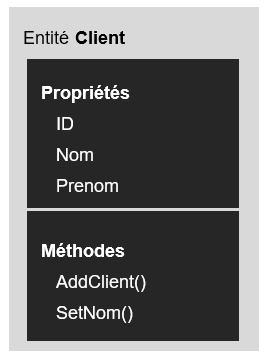
Bien sûr, il est tout à fait possible d’avoir des entités sans méthodes. Cela peut arriver dans des entités enfants très simple où le microservice n’a pas besoin de beaucoup de complexité.
Beaucoup de débat tourne autour du modèle anémique et beaucoup de gens pensent que c’est un anti-pattern. Au final, cela dépend vraiment du contexte de votre projet et du microservice. Pour un microservice très simple, un modèle anémique est certainement ce qu’il vous faut. Cependant, plus la complexité va s’agrandir, plus il est judicieux de construire des modèles de type POCO afin de regrouper au même endroit les règles métiers. Un modèle riche ne sera qu’un plus pour la conception d’un système avec DDD et permettra aux différents microservices de garder leur pérennité sur le long terme.
L’approche DDD est tournée vers le domaine métier, et sa représentation dans le code pour former un système d’information répondant aux problèmes clients de manière la plus efficace possible. Les notions de contexte délimités, de couche d’abstraction, d’entité POCO et de modèle anémique constitues les facettes de cette méthodologie qu’il faut appréhender lorsqu’une architecture microservice est adopté.




